خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته


27,500 تومانشناسه فایل: 5125
1- مقدمه
با توسعه ی روزافزون سخت افزار ها و نرم افزارهای کامپیوتری، مجموعه داده های ظرفیت بالا را میتوان بدون زحمت، ذخیره کرد. اما، این مجموعه داده ها به گونه هستند که کاربران نمی توانند بدون انجام عمل پیش پردازش از آنها استفاده کند و یا آن ها را به صورت دقیق مشخص کنند. یکی از موضوعات میان رشته ای در علوم کامپیوتر به نام داده کاوی، به بررسی مجموعه داده ها میپردازد و در اصل سعی دارد تا از میان مجموعه داده ها، اطلاعات معنی داری را به دست آورده و آن ها را با استفاده از تکنیک هایی چون خوشه بندی، استخراج ویژگی، تستهای آماری و غیره، به صورت خلاصه و مفید ارائه دهد.
انگیزه ی اصلی در این مطالعه، بر روی خوشه بندی تمرکز دارد که یکی از مهمترین سوژه هایی است که محققان به آن پرداخته اند و کاربرد زیادی در دنیای واقعی دارد از جمله در علوم بیوانفورماتیک، یادگیری ماشین، تحلیل تصویر، و شناسایی الگو و تحلیلهای بازاری. در خوشه بندی ها، هدف اصلی تقسیم داده ها به گروه ها و یا خوشه هایی است که بر اساس اندازه گیری شباهت هایی مانند فاصله و یا وقفه بین داده های چند بعدی، صورت میگیرند. از طریق خوشه بندی، میتوان اطلاعات مفیدی را از حجم بسیار زیادی داده ها به دست آورد.
الگوریتمهای خوشه بندی به دو دسته ی کلی تقسیم میشوند، سلسله مراتبی و پارتیشن بندی. الگوریتمهای سلسله مراتبی مبتنی بر استفاده از ماتریسهای همسایگی هستند که این ماتریس ها تعیین کننده ی شباهت بین هر جفت از نقاط داده ای هستند که باید خوشه بندی شوند و نتیجه ی این ماتریس ها به صورت نمودار “دندروگرام” نشان داده میشود که نشان دهنده ی گروه بندیهای تو در تو الگو ها و سطوح شباهت هستند که تغییرات گروه بندی و سطوم از طریق روشهای پایین به بالا و یا بالا به پایین، ایجاد میشود.
در روش انباشتی (پایین به بالا) الگوریتم های سلسله مراتبی، هر عضو داده به یک خوشه ی مشخص تخصیص داده میشود، سپس دو خوشه به صورت مکرر مبتنی بر ماتریس همسایگی یافت میشود و سپس این خوشه ها با هم ادغام میشوند. الگوریتم سلسله مراتبی اصلی نوع انباشتی گامهای زیر را دارد : نخست، یک ماتریس شباهت را ایجاد میکنیم که نشان دهنده ی تفاوت بین هر جفت از داده ها میباشد. سپس، K=N را در نظر میگیریم که N تعداد داده ها و K تعداد خوشه ها است. سپس به صورت مکرر نزدیکترین جفت خوشه های متفاوت را پیدا می کنیم و آنها را با هم ادغام کرده و K را یکی یکی کاهش می دهیم تا زمانی که K > 1 شود.
روند ادغام خوشه ها را میتوان به روشهای مختلف انجام داد، اما معروف ترین روش، پیوند یکتا(تک لینکی) و پیوند کامل میباشد. الگوریتمهای پیوند یکتا بر اساس ادغام دو گروه مختلف ایجاد میشوند که ملاک ادغام دو گروه این است که کمترین فاصله بین نزدیکترین اعضای آن ها وجود داشته باشد. در مقابل، الگوریتمهای پیوند کامل مبتنی بر ادغام گروه هایی است که کمترین فاصله بین دورترین اعضای آن ها وجود دارد.
مشابه الگوریتمهای سلسله مراتبی تقسیم کننده، تمام اعضای داده ها به یک خوشه نسبت داده میشود و سپس یک خوشه در هر مرحله مشخص میشود تا زمانی که تعداد خوشه ها برابر با نقطه داده ها باشد. با وجود این که تعداد خوشه ها از قبل مشخص نمیشود و شرایط اولیه تاثیری بر روند خوشه بندی در الگوریتمهای سلسله مراتبی ندارد، این الگوریتم ها پویا نیستند یعنی، بعد از این که یک نقطه داده به یک خوشه نسبت داده می شود، دیگر نمیتوان خوشه ی آن داده را به روز رسانی کرد و سپس ممکن است نبود اطلاعات در مورد سایز سراسری و شکل اطلاعات، موجب همپوشانی خوشه ها با هم بشود.
بر خلاف الگوریتمهای سلسله مراتبی، الگوریتمهای پارتیشن بندی این امکان را فراهم میکند تا بتوان اعضای خوشه را، در صورتی که موجب بهبود عملکرد خوشه بندی شود، به روز رسانی کرد. روش پارتیشن خوشه بندی تلاش میکند تا داده ها را با استفاده از معیارهای شباهت (مثلا مانند تابع مربع خطا) اطلاعات به مجموعه ای از خوشه های مجزا تجزیه کند که با نسبت دادن نقاط اوجی در تابع چگالی احتمال و یا ساختار سراسری، سعی میشود تا این مقدار را حداقل کرد(عمل تجزیه کردن را). ازین رو، خوشه بندی به روش پارتیشن بندی خوشه را میتوان به عنوان یک مسئله بهینه سازی در نظر گرفت که همچنین در این مقاله، مورد ملاحظه قرار گرفته است. در زمان استفاده از الگوریتمهای خوشه بندی به روش پارتیشن بندی ، عیب های الگوریتمهای سلسله مراتبی برای الگوریتمهای پارتیشن بندی تبدیل به مزیت میشود، و بالعکس.
خوشه بندی را نیز میتوان در دو حالت مختلف مورد استفاده قرار داد: خوشه بندی به حالت کریسپ (سخت) و خوشه بندی به صورت فازی (نرم). الگوریتمهای خوشه بندی به روش کریسپ بر این فرض است که هر الگو باید تنها به یک خوشه نسبت داده شود و خوشه ها مجزا و بدون داشتن همپوشانی هستند. معروف ترین نمونه از خوشه بندی کریسپ ، الگوریتمهای K-میانگین(k-means) هستند. K -میانگین ، با K مقدار از خوشه های از پیش تعیین شده کار را شروع کرده و سپس هر عضو داده را به نزدیک ترین خوشه نسبت میدهد. بعد از مشخص کردن خوشه ی هر داده، مرکز هر خوشه به روز رسانی میشود و این روند تا زمانی که شرط پایانی الگوریتم فراهم شود، تکرار میشود. مشابه خوشه بندی فازی، یک الگو ممکن است به تمام خوشه ها با یک تابع عضویت فازی مشخص نسبت داده شود. (مثلا C -میانگین فازی (FCM))
با این حساب که K میانگین و C میانگین بیش از حد مبتنی بر شرایط اولیه هستند، اصلاحاتی پیشنهاد شده است تا بتوان عملکرد این الگوریتم ها را بهبود داد. علاوه بر این، تکامل مبتنی بر الگوریتمهای خوشه بندی یکی از الگوریتم هایی هستند که برای رفع مشکل گیر کردن در مینیمم های محلی در این روشهای خوشه بندی، پیشنهاد شده اند. الگوریتمهای بهینه سازی ازدحام ذرات(PSO)، در سال 1995 توسط Kennedy و Eberhart ارائه شدند که از این الگوریتم ها در مسئله های خوشه بندی استفاده شد و عملکرد بهتری از این الگوریتم نسبت به K میانگین به دست آمد.
Omran و Al-Sharbanهم از PSO ارائه شده توسط Baribones استفاده کردند تا بتوانند مسئله خوشه بندی تصاویر را انجام دهند. Wong و همکارانش یک نسخه ی بهبود یافته از تابع هدف این الگوریتم را ارائه دادند که نخستین بار توسط Omran و همکارانش ارائه شده بود. در کنار PSO، Hancer و همکارانش یک کلونی زنبور عسل مصنوعی را مبتنی بر روش قطعه بندی تومورهای مغزی تصویرهای MRI ارائه دادند که از تابع هدف مسئله قبلی برای انجام این کار استفاده کردند.
Ozturk و همکارانش مشکلات توابع هدف در مقالات را شناسایی کرده و یک تابع هدفی را توسعه دادند که میتواند نیازهای خوشه بندی های بهم پیوسته و مجزا را برآورده کند. علاوه بر این، بهینه سازی کلونی مورچگان(ACO) هم در مسئله های خوشه بندی مورد استفاده قرار گرفته است. اطلاعات دقیق در این زمینه را میتوانید در مرجعهای 26-23 مشاهده کنید.
واضح است که تعداد خوشه ها را در برنامه کاربردی ها و مجموعه داده هایی دنیای واقعی نمیتوان به آسانی مشخص کرد؛ از ین رو، الگوریتم هایی که در بالا مشخص کردیم که نیازمند تعیین تعداد خوشه ها هستند، نمیتوانند به خوبی در مسائل دنیای واقعی به کار گرفته شود. بر اساس این دانسته ها، یافتن تعداد خوشه ی “بهینه” در مجموعه داده ها تبدیل به یکی از مهم ترین موضوعات تحقیقاتی شده است.
روش پیشنهاد شده توسط Ball و Hall با نام ISO-DATA خوشه ها را از طریق برنامه نویسی های مبتنی بر معیار مشخص، جدا و یا ادغام میکند تا بتواند تعداد خوشه ها را افزایش یا کاهش دهد. اما، ISODATA از کاربر میخواهد تا مقدار چند پارامتر را مشخص کند (از جمله آستانههای تقسیم و یا ادغام خوشه ها) و این روش تنها میتواند بر اساس آستانه مشخص شده توسط کاربر، دو خوشه را با هم ادغام کند.
پویش بهینه و پویای خوشه (DYNOC)، مشابه ISODATA، مبتنی بر بیشینه سازی نسبت فاصله ی درون خوشه ای مینیمم برای ایجاد بیشترین فاصله ی میان خوشه ای(بین خوشه های مختلف باهم-فراخوشه ای) است، اما این روش نیز از کاربر میخواهد تا پارامترهای متعددی را مشخص کند. Snob که برنامه ی Wallace برای طبقه بندی داده هایی با متغیرهای مختلف به صورت بدون سرپرست است، از کمترین طول (پیام و یا توصیف) اصل (MML یا MMD) استفاده می کند تا بهترین طبقه بندی از داده ها را برای تخصیص اشیاء به خوشه ها، مشخص شود.
الگوریتمهای مبتنی بر تکامل هم در مسئله خوشه بندی پویا، مخصوصا در دهه ی اخیر، استفاده شده است. Omran و همکارانش یک الگوریتم خوشه بندی تصویر پویا مبتنی بر PSO (DCPSO) را پیشنهاد دادند که الهام گرفته از ایدههای Kuncheva و Bezdek بود. در DCPSO، یک مجموعه ی خوشه (S) نخست ایجاد شده و سپس PSO باینری برای انتخاب مراکز خوشه از S، مورد استفاده قرار میگیرد.
سپس، مراکز خوشه به دست آمده از S با بهترین راه حل ها توسط K میانگین اصلاح میشود. Das و همکارانش الگوریتمهای مبتنی بر تکامل تفاضلی (ACDEو AFDE) را پیشنهاد دادند که در این روش پارامترهای F -معیار و نرخ کراس اور ژنتیکی (کراس اور) به صورت تطبیقی، تعیین میشود. در ACDE، هر راهکار توسط مراکز خوشه و مقادیر فعال سازی مرتبط (]0و1[)نشان داده میشود. پس از ارزیابی ها، مراکز خوشه و مقادیر فعال سازی آنها به صورت همزمان به روز رسانی میشود. ازین رو، دیگر نیازی به استفاده از K میانگین برای کاهش تاثیر شرایط اولیه -مشابه روش DCPSO – نمی باشد. Kuo و همکارانش یک الگوریتم ترکیبی PSO&GA را بهبود دادند تا بتوانند بر مشکلات همگرایی در الگوریتم PSO غلبه کنند.
هر چند، تابع فیت نس(برازش/برازندگی) هدف مورد استفاده شده مبتنی بر فاصله ی اقلیدسی، برای مسئله خوشه بندی پویا خیلی مناسب نیست. Maulik و Saha یک الگوریتم خوشه بندی تکاملی تفاضلی اصلاح شده را مبتنی بر اطلاعات مکان های بهینه ی محلی و سراسری (MoDEAFC) پیشنهاد دادند تا بتواند به صورت خودکار اطلاعات را از تصاویر حسی از دور، استخراج کند. Rui و همکارانش، از DE و PSO به صورت ترتیبی برای تکرارهای فرد و زوج استفاده کردند و یک مطالعه ی مقایسه ها بر روی شاخص های اعتبارسنجی خوشه بندی، ارائه دادند.
هدف اصلی این مطالعه، این است که نشان دهیم، نسخه ی بهبود یافته گسسته و باینری کلونی زنبور عسل مصنوعی (DisABC) می تواند در مسئله های خوشه بندی پویا، مورد استفاده قرار گیرد. نوآوری نسخه ی بهبود یافته ی کلونی زنبور عسل مصنوعی گسسته(که به آن IDisABC می گویند) شامل دو بخش میشود: انتخاب تصادفی اصلاح شده و انتخاب حریصانه اصلاح شده، میباشد.
این مکانیسم های اصلاح شده انتخاب، زمانی که تعداد مسائل بدست امده خروجیها (بر اساس محاسبه ی عدم تشابه دو راه حل مجاور به هم) بیشتر از مقدار یک باشد، با استفاده از عملگرهای کراس اور و مبادله در فضای جستجوی حل مسئله ها، مورد استفاده قرار میگیرد . به این صورت، پیچیدگیهای محاسباتی الگوریتم ها خیلی تحت تاثیر قرار نمیگیرد.
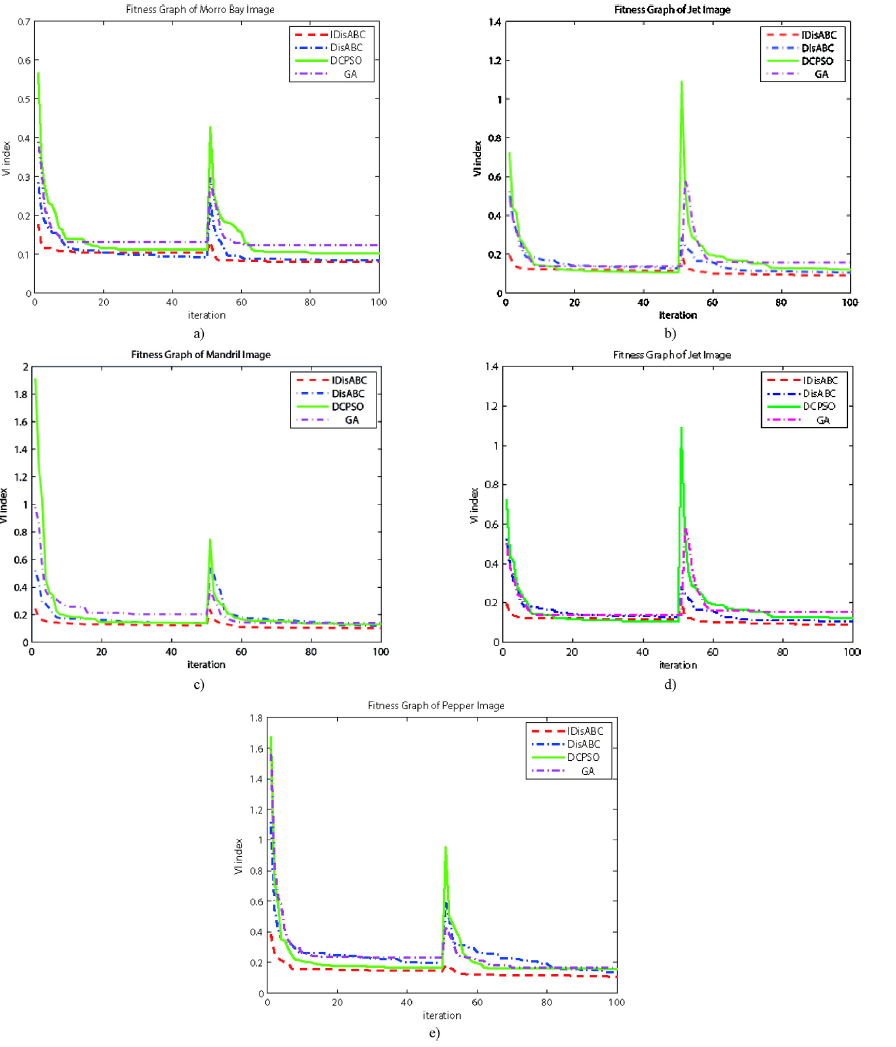
علاوه بر این، تحلیل عملکرد و مقایسه های عملکردی الگوریتم ها، از نظر شاخص کیفیت ، تعداد خوشه به دست آمده و درصد طبقه بندی صحیح(CCP) آزمایش و بنچ مارک(benchmark) شده اند و با اعمال الگوریتمهای استاتیک مانند K میانگین و FCM به علاوه ی الگوریتمهای تکاملی کامپیوتری شامل DCPSO، GA و DisABC،مورد ارزیابی قرار گرفته است. باید این موضوع را در نظر داشت که CCP یکی از معروف ترین معیار ها برای اندازه گیری کیفیت خوشه بندی میباشد ؛ اما، مطالعات اندکی ،مخصوصا آنهایی که در رابطه با خوشه بندی پویا هستند، مقادیر CCP را اعلام کرده اند.
ادامه ی این مقاله به صورت زیر می باشد؛ بخش 2 الگوریتم ABC را توصیف می کند؛ بخش 3 الگوریتم IDisABC را نشان میدهد؛ بخش 4 مسئله ی خوشه بندی را تعریف میکند؛ و بخش 5 نشان دهنده ی نتایج مقایسه ای جدیدترین الگوریتم ها و الگوریتم پیشنهاد شده میباشد. در نهایت، بخش 6 مقاله را جمع بندی میکند.
ABSTRACT Dynamic clustering with improved binary artificial bee colony algorithm
One of the most well-known binary (discrete) versions of the artificial bee colony algorithm is the similarity measure based discrete artificial bee colony, which was first proposed to deal with the uncapacited facility location (UFLP) problem. The discrete artificial bee colony simply depends on measuring the similarity between the binary vectors through Jaccard coefficient. Although it is accepted as one of the simple, novel and efficient binary variant of the artificial bee colony, the applied mechanism for generating new solutions concerning to the information of similarity between the solutions only consider one similarity case i.e. it does not handle all similarity cases. To cover this issue, new solution generation mechanism of the discrete artificial bee colony is enhanced using all similarity cases through the genetically inspired components. Furthermore, the superiority of the proposed algorithm is demonstrated by comparing it with the basic discrete artificial bee colony, binary particle swarm optimization, genetic algorithm in dynamic (automatic) clustering, in which the number of clusters is determined automatically i.e. it does not need to be specified in contrast to the classical techniques. Not only evolutionary computation based algorithms, but also classical approaches such as fuzzy C-means and K-means are employed to put forward the effectiveness of the proposed approach in clustering. The obtained results indicate that the discrete artificial bee colony with the enhanced solution generator component is able to reach more valuable solutions than the other algorithms in dynamic clustering, which is strongly accepted as one of the most difficult NP-hard problem by researchers.







- مقاله درمورد خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته
- پروژه دانشجویی خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته
- کاربرد الگوریتم باینری کلونی زنبور عسل در خوشه بندی دینامیک
- پایان نامه در مورد خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته
- تحقیق درباره خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته
- مقاله دانشجویی خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته
- خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته در قالب پاياننامه
- پروپوزال در مورد خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته
- گزارش سمینار در مورد خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته
- گزارش کارورزی درباره خوشه بندی دینامیک توسط الگوریتم باینری کلونی زنبور عسل بهبود یافته