آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک
 MECS Publisher
وولوم 5
ایژو 12
صفحات 31-39
سال انتشار 2013شاپا الکترونیک: 2075-017X
MECS Publisher
وولوم 5
ایژو 12
صفحات 31-39
سال انتشار 2013شاپا الکترونیک: 2075-017Xشاپا پرینت: 2075-0161 رفرنس دارد وبسایت مرجع
19,500 تومانشناسه فایل: 8205
چکیده
همانطور که وب روز به روز گسترش می یابد و مردم برای برقرای ارتباط به وب ها تکیه می کنند، بنابراین ایمیل ها سریع ترین راه برای ارسال اطلاعات از یک مکان به مکان دیگر است. در حال حاضر تمام ارتباطات، چه خصوصی چه تجاری همه از طریق پست الکترونیکی انجام می گیرد. ایمیل یک ابزار موثر برای ارتباطات است و سبب صرفه جویی در وقت و هزینه می شود. اما ایمیل ها نیز با حمله ها و تهاجمی به نام Spam رو به رو هستند. هرزنامه از سیستم پیام الکترونیکی استفاده می کند که حجم زیادی از حافظه را می گیرد. هرزنامه ها همچنین خیلی در دنیای اینترنت رایج شده است و یک سری پیام ها را کپی می کند و تلاش می کند تا پیام را برای افرادی که در غیر این صورت تصمیم به دریافت آن را نخواهند، تحویل دهند. در این مطالعه، به بررسی روش های استفاده و بهره برداری از اطلاعات Spam می پردازیم تا بهترین دسته بندی را در ایمیل پیدا کنیم. در این مقاله، عملکرد دسته بندی های مختلف با الگوریتم انتخاب مشخصه ها و بدون مشخصه ها تحلیل می کنیم. در ابتدا بدون انتخاب این مشخصه ها داده ها را آزمایش می کنیم و دسته ها را به صورت یک به یک انجام می دهیم و نتایج را بررسی می کنیم. سپس برای انتخاب بهترین الگوریتم را برای انتخاب ویژگی های دلخواه اعمال می کنیم. در این مطالعه مشخص شده است که با فرآیند انتخاب ویژگی نتایج دارای بهبود قابل توجهی هستند. در نهایت، ما یک درخت تصادفی برای پیدا کردن بهترین طبقه بندی کننده برای Spam با دقت ۷۲/۹۹ درصد یافت شد. هنوز هیچ کدام از الگوریتم ها به دقت ۱۰۰ درصد نرسیده اند اما این الگوریتم تقریبا به این مقدار نزدیک است.
مقدمه مقاله
ایمیل یک راه موثر برای برقراری ارتباط است که موجب صرفه جویی در وقت و هزینه می شود و در برای ارتباطات شخصی و حرفه ای می توان از آن کمک گرفت. ایمیل یک راه را برای کاربران اینترنت ایجاد کرده است که در سر تا سر دنیا با هم در ارتباط باشند.
اما مواردی هم وجود دارد که ایمیل شما تحت حملات افراد یا نرم افزار ها به صورت فعال یا غیر فعال واقع شود. برخی مواقع ما ایمیلی از منابع ناشناس یا ایمیل هایی که محتوای آن ها ارتباطی با ما ندارد دریافت می کنیم. این ایمیل ها را Spam می نامیم. ایمیل های اسپم که شامل اطلاعات ناخواسته و حجیم است به تعداد زیاد برای کاربران فرستاده می شود. ایمیل های Spam یک زیر مجموعه از Spam الکترونیکی است که در قالب یک پیام به ایمیل های متفاوت ارسال می شود. ایمیل های اسپم شامل یک سری دست نوشته ها یا یک سری فایل های اجرایی است. در کل دو نوع مختلف هرزنامه وجود دارد و دارای اثرات متفاوت روی کاربران اینترنتی است. Usenet های قابل کنسل کردن یک سری پیام هستند که به ۲۰ یا بیشتر گروه Usenet ارسال می شود. هدف Usenet Spam این است که در کمین افرادی که گروه های خبری را مطالعه می کنند، می نشینند و خیلی کم توسط این افراد به اشتراک گذاشته می شوند. Usenet Spam توانایی نابود کردن سیستم های اداری را به منظور مدیریت در سیستم های آن ها را دارد. انواع دیگر ایمیل های اسپم به منظور هدف خاصی و برای افراد خاصی ارسال می گردند. لیست ایمیل های هرزنامه با اسکن کردن در Usenet و دزدیدن لیست ایمیل های اینترنتی امکان پذیر است. ایمیل اسپم ایمیلی است که دارای سه معیار زیر است:
- بی نام و نشان: آدرس و مشخصات ارسال کننده پنهان است.
- ایمیل های انبوه: ایمیل به افراد زیادی ارسال می شود.
- بدون درخواست: این ایمیل ها توسط دریافت کننده ها درخواست نشده است.
ایمیل های Spam یکی از بزرگترین مشکلات در سال های اخیر شده است. تقریبا ۷۰ درصد از ایمیل ها به صورت هرزنامه هستند و با توجه به گسترش وب سایت ها این قضیه حاد تر شده است. در [۱] ذکر شده است که تقریبا ۱۰ روز کامل در سال برای حذف کردن ایمیل های اسپم نیاز است. اسپم یکی از گران ترین مشکلات است که سبب شده تا کاربران هر ساله میلیون ها دلار برای افزایش پهنای باند شبکه هزینه کنند و هرزنامه قابلیت حمله کردن به پیام های الکترونیکی را دارد. بنابراین تمیز بین ایمیل و Spam خیلی ضروری است و روش های زیادی برای دسته بندی این ایمیل ها و اسپم ارائه شده است [۲].
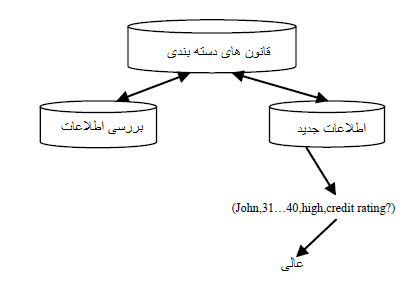
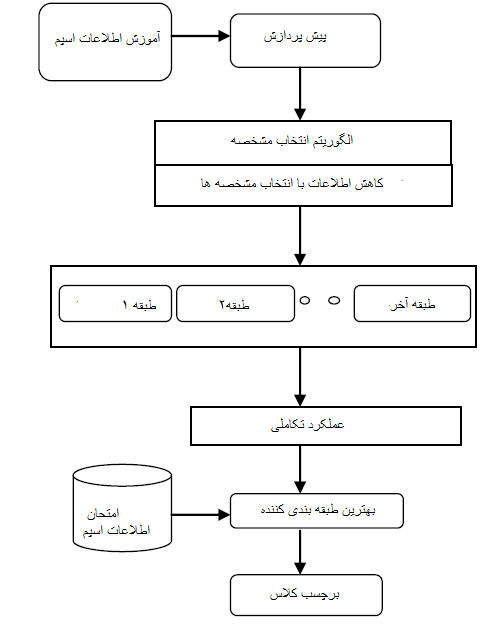
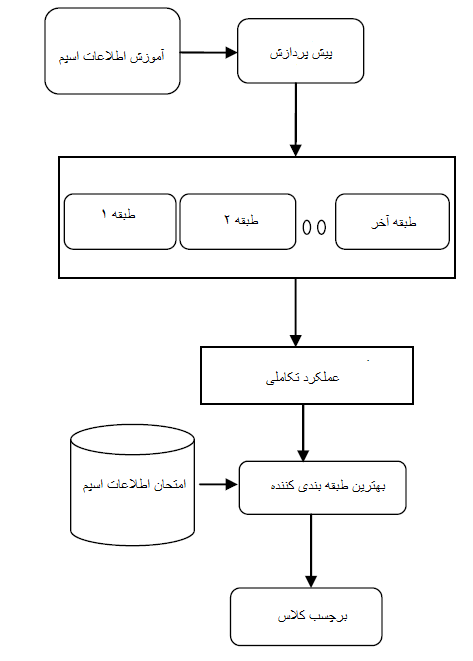
چندین الگوریتم برای طبقه بندی ایمیل های اسپم و استفاده از آن ها و آنالیز آن ها ارائه شده است که شامل درخت تصمیم گیری، شبکه های عصبی مصنوعی و غیره. در این مقاله ما از الگوریتم های Naïve Bayes، Bayes Net، ماشین های تامین کننده، درخت تابع، J48، جنگل و درخت احتمالی استفاده خواهیم کرد. در ابتدا ما آزمایش و کار خود را روی ۵۸ مشخصه و تعداد اعضای کلی ۴۶۰۱ می باشد. ما الگوریتم ارائه شده را یکی یکی روی اطلاعات پیاده سازی خواهیم کرد و سپس نتایج را بررسی می کنیم همان طور که از طبقه بندی جنگل و طبقه بندی درخت فهمیده می شود این الگوریتم دارای نتیجه خوب و دقیقی برای تشخیص ایمیل های اسپم دارد.
به منظور مقایسه نتایج با کار های طبقه بندی شده برای دریافتن ویژگی های الگوریتم پیشنهادی، الگوریتم انتخاب ویژگی را روی یک سری اطلاعات پیاده سازی خواهیم کرد. در بیشتر از ۵۸ مشخصه تنها ۱۵ تای آن ها برای کار های ذکر شده انتخاب شده اند. با این مطالعات فهمیده می شود که دقت همه طبقه بندی کننده ها. موقعی که ما ویژگی را از بین بهترین الگوریتم انتخاب می کنیم، بهبود پیدا می کند. همچنین هنگامی که طبقه بندی کننده ها را مقایسه می کنیم مشاهده می کنیم که درخت های تصادفی نتیجه بهتری را شامل شده است.
این مقاله به شرح زیر است: بخش ۲، شامل بررسی کارهای انجام شده، بخش ۳، مربوط به کار های انجام شده، بخش ۴، ارائه کار آزمایشی و نتایج، بخش ۵، ارائه نتایج تجربی و در بخش ۶ نتیجه گیری و کار های آینده ارائه شده است.
ABSTRACT Spam Mail Detection through Data Mining – A Comparative Performance Analysis
As web is expanding day by day and people generally rely on web for communication so e-mails are the fastest way to send information from one place to another. Now a day’s all the transactions all the communication whether general or of business taking place through e-mails. E-mail is an effective tool for communication as it saves a lot of time and cost. But e-mails are also affected by attacks which include Spam Mails. Spam is the use of electronic messaging systems to send bulk data. Spam is flooding the Internet with many copies of the same message, in an attempt to force the message on people who would not otherwise choose to receive it. In this study, we analyze various data mining approach to spam dataset in order to find out the best classifier for email classification. In this paper we analyze the performance of various classifiers with feature selection algorithm and without feature selection algorithm. Initially we experiment with the entire dataset without selecting the features and apply classifiers one by one and check the results. Then we apply Best-First feature selection algorithm in order to select the desired features and then apply various classifiers for classification. In this study it has been found that results are improved in terms of accuracy when we embed feature selection process in the experiment. Finally we found Random Tree as best classifier for spam mail classification with accuracy = 99.72%. Still none of the algorithm achieves 100% accuracy in classifying spam emails but Random Tree is very nearby to that.
Introduction
E-Mail is an effective way of communication as it saves a lot of time and money this makes it as a favourite means of communication in personal as well as in professional communication. E-mails provide a way for internet users to easily transfer information globally.
But there is also a case when your e-mails are affected by attacks whether active or passive. Sometimes we receive e-mail from unknown source and also e-mail comprised of contents which is of no importance to the user. These kind of unwanted mails are better known as Spam Mails. Spam email is the practice of frequently sending unwanted data or bulk data in a large quantity to some email accounts. Spam Mail is a subset of electronic spam involving nearly identical messages sent to various recipients by email. Spam mails also include malware as scripts or other executable file attachment. There are two main types of spam and they have different affects on Internet users. Cancellable Usenet spam is a single message sent to 20 or more Usenet groups. Usenet spams aims at “lurkers”, people who read newsgroups but rarely or never post and give their address away. Usenet spam subverts the ability of system administrator to manage the topics they accept on their systems. Another type of Email spam targets individual users with direct mail messages. Email spam list are created by scanning Usenet postings, stealing Internet mailing list. Email spam is any email that meets the following three criteria:
- Anonymity: The address and identity of the sender are concealed.
- Mass Mailing: The email is sent to large group of people.
- Unsolicited: The email is not requested by recipients.
Spam Mail has become an increasing problem in recent years. It has been estimated that around 70% of all emails are spam. As the usage of web expanding, problem of spam mails are also expanding. According to [1] it has been found that on an average 10 days per year waste on dealing with spam mails only. Spam is an expensive problem that costs billion of dollars per year to service providers for lost of bandwidth. Spam is a major problem that attacks the existence of electronic messages. So it is very essential to distinguish emails from spam mails, many methods have been proposed for classification of email messages as spam mail or legitimate mail and it has been found that machine learning algorithm success ratio for classification is very high [2].
Several algorithms are used for classification of spam mails which are extensively utilize and analyze out of which support vector machine, Naïve Bayes, Decision Tree, Neural network classifiers are well known classifiers. In this paper we experiment our data set with these given algorithms: Naïve Bayes, Bayes Net, Support vector machine (SVM), function Tree (FT), J48, Random Forest and Random Tree. Initially we experiment on entire data set which consists of total 58 attributes and total number of instances is 4601. We apply above mentioned algorithm one by one on the data set and check the result and it is retrieved from the study that out of all these classifiers Random Forest and Random Tree works well and gives accuracy better than other classifiers in detection of spam mails. In order to compare the result that classifiers works well with some attributes selected or not, then we apply Feature selection algorithm on the same dataset (the algorithm we used here is Best First Search algorithm) and apply the same classifiers with features selected. Out of 58 features only 15 features are selected and apply the same above mentioned algorithm on this reduced dataset.
From this study it is found that all classifier’s accuracy improved when we select features through Best-First algorithm. Again when compared with all classifiers which we experimented on this reduced data set Random Tree shows better results in context of accuracy.
This paper is organized as follows: Section 2 comprised of Background study, Section 3 presents related work, Section 4 presents the Experimental work and results, Section 5 presents Experimental Results and Section 6 presents conclusion and future work.
- مقاله درمورد آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک
- پروژه دانشجویی آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک
- تشخیص اسپم در بین اطلاعات به دست آمده پست الکترونیک
- پایان نامه در مورد آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک
- تحقیق درباره آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک
- مقاله دانشجویی آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک
- آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک در قالب پاياننامه
- پروپوزال در مورد آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک
- گزارش سمینار در مورد آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک
- گزارش کارورزی درباره آنالیز عملکرد نسبی تشخیص Spam میان اطلاعات جمع آوری شده پست الکترونیک