کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان

28,700 تومانشناسه فایل: 8149
مقدمه مقاله
دسته بندی متون، نقش بسیار مهمی را در توسعه اطلاعات متنی وب سایت ها، بالاخص در شبکه های اجتماعی ، وبلاگ ها وب سایت ها ایفا می کند. هرچه بیشتر افراد در این شبکه ها و وب سایت ها ، حضور به هم رسانند و در آن جا شرکت کنند، تعداد این داده ها بیشتر خواهد شد. دسته بندی متون ، به عنوان سامان دهید خودکار اسناد بر مبنای دسته بندی های از پیش تعیین شده، تعریف می شود. الگوریتم دسته بندی متون، به مقیاس فاصله و یا مقیاس شباهت متن هایی بستگی دارد که اسناد آن ها را با هم مقایسه می کنیم. مقیاس شباهت، نقش بسیار مهمی را در دسته بندی اسناد، بازی می کند. نوع داده های ساختار بندی شده و داده های متنی که شامل اطلاعات معنایی می باشند، بر طبق واژگان اسناد ، تغییر می یابند. بنابراین الگوریتم دسته بندی، از اطلاعات معنایی، بر حسب رسیدن به نتایج بهینه استفاده می کند.
در حوزه دسته بندی داده های متنی، اسناد، به شکل واژگان و میزان فراوانی آنها ، نشان داده می شوند. این رویکرد نمایشی، یک از مهم ترین رویکردهایی است که ویژگی ” مجموعه ای از واژگان” (BOW) نامیده می شود. در این رویکرد، هر واژه، متشکل از یک بعد در فضای برداری می باشد که مستقل از دیگر واژگان در همان اسناد است. (سالتون و یانگ 1973). رویکرد BOW، بسیار ساده است و به صورت متداول، مورد استفاده قرار می گیرد، هرچند که هنوز، محدودیت های خاص خود را دارد. محدودیت اصلی این رویکرد، استقلال و عدم وابستگی، بین واژگان می باشد.
از این رو اسناد در این مدل، با توجه به واژگان خود، نشان داده می شوند که در اصل، موقعیت آن ها در متن و یا بعد معنایی آن ها و یا ارتباط نحوی بین واژگان دیگر، نادیده گرفته شده است. بنابراین ما می توانیم برای سهولت در کار خود، چندین واژه را به چندین قسمت مختلف تقسیم بندی کنیم. همین کار را هم باید ، برای واژگان چند معنایی در یک واحد استفاده کنیم. به طور مثال واژه ارگان، به اندام انسان بر می گردد، البته اگر در متون بیولوژی و زیست شناسی، مورد استفاده قرار گیرد. اما ، ممکن است در متن موسیقی، به معنای آلات موسیقی باشد. به علاوه، ما باید به کلمات مترادف با اجزای مختلف، توجه کنیم. (وانگ و دومنیکن، 2008). استینباخ و همکاران (2000)، در رابطه با این بحث ، بیان کردند که هر دسته بندی واژگانی، دارای دو نوع واژه و لغت می باشد : یکی هسته واژه است که به موضوع دسته بندی بر می گردد و دیگری، کل واژه می باشد که دارای توزیع یکسانی در دسته بندی های مختلف می باشد. بنابراین دو سندی که از دسته بندی های مختلف گرفته شده اند، می توانند واژگان کلی و تعمیم یافته را با هم به اشتراک گذاشته و نمایش BOW را مد نظر قرار دهند.
ما در راستای این مسئله، چندین روش را به شما پیشنهاد می کنیم که از مقیاس ارتباط بین واژگان در وضوح معنایی واژگان (WSD)، حوزه دسته بندی بازیابی اطلاعات و متن، استفاده می کند. ارزیابی رابطه معنایی، بر حسب سیستم بر مبنای دانش، رویکرد های آماری و روش ترکیبی ای انجام می شود که متشکل از اطلاعات آماری و هستی شناسی (آنتالوژی) می باشد. (نصیر و همکاران، 2013).سیستم بر مبنای دانش، از نظریه هستی شناسی ، برای بالا بردن نمایش واژگان استفاده می کند و دارای روابط معنایی بین واژگان می باشد. به طور مثال : لی و همکاران 1993، ……نام نویسندگان در ص 2). به طور مثال ، (بلودورن، 2006) و (سیولاس، 2000)، بیان می کنند که از فاصله بین واژگان در WordNet، برای شباهت معنایی بین کلمات استفاده می کنیم.تحقیق (بلوهورن و همکاران، 2006)، از بیانیه های مفهومی با توجه به مقیاس فاصله بین دو واژه متفاوت برگرفته شده از WordNet، استفاده کردند. مثل IPL(طول فاصله تغییر یافته)، مقیاس Wu-Palmer،مقیاس Resnik. تحقیقات اخیر ژانگ و همکاران (2013) از HowNet استفاده کردند که دانش معنایی به زبان چینی می باشد. دومین نوع محاسبه ارتباط معنایی بین واژگان، سیستم بر مبنای مجموعه متون و نوشته هایی می باشد که در آن ، تحلیل های آماری، بر حسب رابطه این واژگان در مجموعه اسناد آموزشی انجام شده تا شباهت نهانی بین واژگان را نشان دهد. (ژانگ 2012). یکی از مشهورترین سیستم ها بر مبنای مجموعه داده های متنی، تحلیل معنای پنهانی (LSA) می باشد که مشکل مترادف ها را حل می کند. در نهایت، رویکرد آخری، رویکرد ترکیبی نامیده می شود. از این رو آن ها، اطلاعات بدست آمده از تحلیل های آماری و هستی شناسی مجموعه متون و داده ها را با هم ترکیب می کنند.(نصیر و همکاران،2013). تحقیقات اخیر ژانگ و همکاران هم در این زمینه بود.
ما در تحقیقات قبلی، چندین کرنل معنایی بر مبنای مجموعه ای از متون و نوشته ها مثل HOSK( کرنل معنایی با رتبه بالا) ، (آلتونل و همکاران، 2013)، IHOSK (کرنل معنایی با تکرار رتبه بالا)، _آلتونل و همکاران، 2014) و HOTK( کرنل واژه ای رتبه بالاتر ) پیشنهاد دادیم. ما در این تحقیقات، اهمیت بهبود عملکرد دسته بندی را در کرنل های سنتی SVM مثل کرنل خطی، کرنل چند جمله ای و کرنل RBF را به واسطه مزیت رابطه ترتیبی بین واژگان و اسناد، نشان می دهیم. به طور مثال HOSK، بر مبنای رابطه ترتیبی بین اسناد می باشد. IHOSK ، نیز شبیه به HOSK می باشد. از این رو هر دوی آن ها، از طریق استفاده از رتبه های بالاتر،یک کرنل معنایی را برای SVM نشان می دهند .اگرچه ، IHOSK، از مسیر رتبه بالاتر بین هر دو سند و واژگان پشت سر هم استفاده می کند. بنابراین عملکرد IHOSK، اولویت دارد و پیچیدگی آن، بیشتر از کرنل های دیگر می باشد. یک رویکرد ساده به نام HOTK، از مسیرهای ترتیبی بین واژگان استفاده می کند. این مدل شبیه به الگوریتم های یادگیری رتبه بالاتر (HONB) (گانیز و همکاران، 2009) و HOS (smoothing با رتبه بالاتر) (پویراز و همکاران، 2014) می باشد.
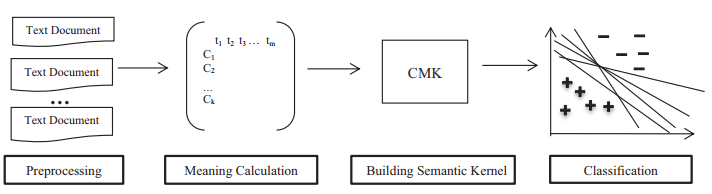
ما در این مقاله، رویکرد جدیدی را برای کرنل معنایی SVM پیشنهاد می دهیم که نام آن ، CMK (کرنل معنایی کلاس ها(دسته بندی ها) می باشد. این رویکرد پیشنهادی، روند نمایش واژگان اسناد را بر مبنای ارزش کلاسی واژگان، در BOW نشان می دهد. (بردار سند، از طریق فراوانی واژگان ، نشان داده می شود). در ضمن، این رویکرد،اهمیت معنای واژگانی را برای هر کلاس افزایش داده و در عین حال، از اهمیت کل واژگانی، می کاهد که برای مجزا کردن کلاس ها و دسته بندی ها، مفید نمی باشند. این رویکرد، معایب BOW که در بالا قید کردیم را کاهش داده و توانایی پیش بینی را در مقایسه با کرنل های خطی استاندارد،آن ها از طریق افزایش اهمیت دسته بندی مفاهیم خاصی، افزایش می دهد. این مفاهیم، با هم مترادف بوده و در یک کلاس و دسته بندی، به هم مربوط و مرتبط می باشند. رویکرد مورد هدف ما، بر روی استفاده از این دسته بندی اطلاعات خاص در فرآیند هموار(smoothing) کرنل معنایی، تاکید دارد. ارزش معنایی این واژگان، مطابق با اصل Helmholtz( Balinsky و همکاران،2010 ، 2011)، برگرفته شده از نظریه Gestalt، بر مبنای زمینه این دسته بندی ها ،مورد ارزیابی قرار می گیرد.
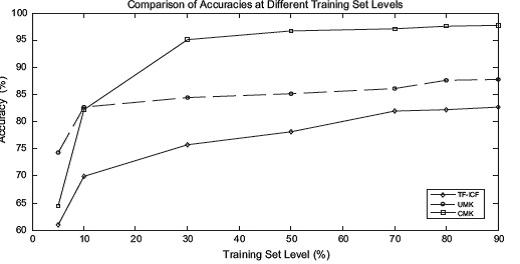
ما چندین آزمون بر روی پایگاه داده های مختلف ، انجام دادیم و پارامترها را بالاخص در زمینه مجموعه های آموزشی، مورد ارزیابی قرار دادیم. نتایج آزمایشی ما نشان دادند که CMK، عملکرد کرنل های دیگر، مثل کرنل خطی، کرنل چند جمله ای و RBF را مورد بررسی قرار می دهد. لطفا توجه داشته باشید که SVM ای با کرنل خطی پذیرفته می شود، به عنوان بهترین عملکرد الگوریتمی، جهت دسته بندی متون مورد توجه قرار گرفته است و در محیط مجازی، مطابق با استاندارد ها نمی باشد. در کرنل خطی، رابطه درونی بین دو بردار سند، به عنوان تابع کرنل مورد استفاده قرار می گیرد که شامل اطلاعاتی راجع به واژگانی می باشد که این اسناد را به اشتراک می گذارند. این رویکرد، به عنوان روش first-order (اولین رتبه)، مورد توجه قرار گرفته و زمینه ها و دیدگاه آن، شامل تنها خود اسناد می باشد. اگرچه، CMK، می تواند از ارزش های معنایی واژگان برای همه کلاس ها و دسته بندی، استفاده کند. اگر این دو واژه، بر حسب یک طبقه مشخص، از اهمیت بالایی برخوردار باشند، پس ارزش مربوط به ارتباطات معنایی، نیز، به طبع، بالاتر خواهد رفت. CMK، در مغایرت با سایر کرنل های معنایی که در وضعیت های نظارت نشده، از WordNet و یا Wikipedia، استفاده می کنند، مستقیما با دسته بندی اطلاعات، در کرنل معنایی در ارتباط است. بنابراین ، CMK، به عنوان کرنل معنایی نظارت شده مورد توجه قرار می گیرد.
یکی از مهم ترین مزیت این رویکرد فرضی، پیچیدگی نسبتا پایین آن می باشد. CMK، نسبت به رویکردهای مبتنی بر دانش و پیش زمینه های آن، از پیچیدگی کمتر و از انعطاف پذیری بیشتری، برخورد دارمی باشد. ازاین رو CMK، بر مبنای مجموعه نوشته ها، ساخته شده و همیشه به روز رسانی می شود. به همین نحو، این رویکرد، هیچ مشکلی در زمینه رابطه معنایی بین واژگانی که به دامنه خاصی از نوشته ها مربوط هستند، ندارد. مزیت دیگر CMK، به شرح زیر می باشد: CMK، به راحتی می تواند با پیش زمینه سیستم های بر مبنای دانش ترکیب شود که از Wikipedia و یا WordNet استفاده می کنند. در نتیجه، CMK، بیشتر بر حسب دقت واژگان و زمان اجرا، شبیه به رویکرد های مشابه بوده که نتایج برگرفته از آن، در آزمایشات ما مشهود است.
بقیه مقاله به شرح زیر ساماندهی شده است:
قسمت 2 ، به پیش زمینه اطلاعات مرتبط با رویکردهای SVM، کرنل های معنایی و محاسبات معنایی، اختصاص داده شده است. قسمت 3، تجزیه و تحلیل کرنل فرضی را برای الگوریتم دسته بندی متون، نشان می دهد. تنظیمات آزمایشی، در قسمت 4 و نتایج آزمایشی ، شامل نکات مورد نظر در مباحث، در قسمت 5، مورد بررسی قرار می گیرند. در نهایت، ما نتیجه گیری ها را به قسمت 6 اختصاص داده و در این قسمت، راجع به کارهای آینده، بحث خواهیم کرد.
ABSTRACT A corpus-based semantic kernel for text classification by using meaning values of terms
Text categorization plays a crucial role in both academic and commercial platforms due to the growing demand for automatic organization of documents. Kernel-based classification algorithms such as Support Vector Machines (SVM) have become highly popular in the task of text mining. This is mainly due to their relatively high classification accuracy on several application domains as well as their ability to handle high dimensional and sparse data which is the prohibitive characteristics of textual data representation. Recently, there is an increased interest in the exploitation of background knowledge such as ontologies and corpus-based statistical knowledge in text categorization. It has been shown that, by replacing the standard kernel functions such as linear kernel with customized kernel functions which take advantage of this background knowledge, it is possible to increase the performance of SVM in the text classification domain. Based on this, we propose a novel semantic smoothing kernel for SVM. The suggested approach is based on a meaning measure, which calculates the meaningfulness of the terms in the context of classes. The documents vectors are smoothed based on these meaning values of the terms in the context of classes. Since we efficiently make use of the class information in the smoothing process, it can be considered a supervised smoothing kernel. The meaning measure is based on the Helmholtz principle from Gestalt theory and has previously been applied to several text mining applications such as document summarization and feature extraction. However, to the best of our knowledge, ours is the first study to use meaning measure in a supervised setting to build a semantic kernel for SVM. We evaluated the proposed approach by conducting a large number of experiments on well-known textual datasets and present results with respect to different experimental conditions. We compare our results with traditional kernels used in SVM such as linear kernel as well as with several corpus-based semantic kernels. Our results show that classification performance of the proposed approach outperforms other kernels.
Introduction
Text categorization plays a significantly important role in recent years with the rapid growth of textual information on the web, especially on social networks, blogs and forums. This enormous data increases by the contribution of millions of people every day. Automatically processing these increasing amounts of textual data is an important problem. Text classification can be defined as automatically organizing documents into predetermined categories. Several text categorization algorithms depend on distance or similarity measures which compare pairs of text documents. For this reason similarity measures play a critical role in document classification. Apart from the other, structured data types, the textual data includes semantic information, i.e., the sense conveyed by the words of the documents. Therefore, classification algorithms should utilize semantic information in order to achieve better results.
In the domain of text classification, documents are typically represented by terms (words and/or similar tokens) and their frequencies. This representation approach is one of the most common one and it is called Bag of Words (BOW) feature representation. In this representation, each term constitutes a dimension in a vector space, independent of other terms in the same document (Salton and Yang, 1973). The BOW approach is very simple and commonly used; yet, it has a number of restrictions. Its main limitation is that it assumes independency between terms, since the documents in BOW model are represented with their terms ignoring their position in the document or their semantic or syntactic connections between other words. Therefore it clearly turns a blind eye to the multi-word expressions by breaking them apart. Furthermore, it treats polysemous words (i.e., words with multiple meanings) as a single entity. For instance the term “organ” may have the sense of a body-part when it appears in a context related to biological structure, or the sense of a musical instrument when it appears in a context that refers to music. Additionally, it maps synonymous words into different components; as mentioned by Wang and Domeniconi (2008). In principle, as Steinbach et al. (2000) analyze and argue, each class has two types of vocabulary: one is “core” vocabulary which are closely related to the subject of that class, the other type is “general” vocabulary those may have similar distributions on different classes. So, two documents from different classes may share many general words and can be considered similar in the BOW representation.
In order to address these problems several methods have been proposed which use a measure of relatedness between term on Word Sense Disambiguation (WSD), Text Classification and Information Retrieval domains. Semantic relatedness computations fundamentally can be categorized into three such as knowledge based systems, statistical approaches and hybrid methods which combine both ontology-based and statistical information (Nasir et al., 2013). Knowledge-based systems use a thesaurus or ontology to enhance the representation of terms by taking advantage of semantic relatedness among terms, for examples see (Bloehdorn et al., 2006), (Budanitsky and Hirst, 2006), (Lee et al., 1993), (Luo et al., 2011), (Nasir et al., 2013), (Scott and Matwin, 1998), (Siolas and d’Alché-Buc, 2000), and (Wang and Domeniconi, 2008). For instance in (Bloehdorn et al., 2006), (Siolas and d’Alché-Buc, 2000) the distance between words in WordNet (Miller et al., 1993) is used to capture semantic similarity between English words. The study in (Bloehdorn et al., 2006) uses super-concept declaration with different distance measures between words from WordNet such as Inverted Path Length (IPL), Wu-Palmer Measure, Resnik Measure and Lin Measure. A recent study of this kind can be found in (Zhang, 2013), which uses HowNet as a Chinese semantic knowledge-base. The second type of semantic relatedness computations between terms are corpus-based systems in which some statistical analysis based on the relations of terms in the set of training documents is performed in order to reveal latent similarities between them (Zhang et al., 2012). One of the famous corpus-based systems is Latent Semantics Analysis (LSA) (Deerwester et al., 1990) that partially solves the synonymy problem. Finally, approaches of the last category are called hybrid since they combine the information acquired both from the ontology and the statistical analysis of the corpus (Nasir et al., 2013), (Altınel et al., 2014a). There is a recent survey in (Zhang et al., 2012) about these studies.
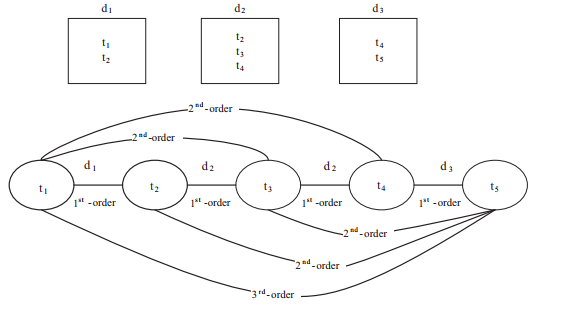
In our previous studies, we proposed several corpus-based semantic kernels such as Higher-Order Semantic Kernel (HOSK) (Altınel et al., 2013), Iterative Higher-Order Semantic Kernel (IHOSK) (Altınel et al., 2014a) and Higher-Order Term Kernel (HOTK) (Altınel et al., 2014b) for SVM. In these studies, we showed significant improvements on classification performance over traditional kernels of SVM such as linear kernel, polynomial kernel and RBF kernel by taking advantage of higher-order relations between terms and documents. For instance, the HOSK is based on higher-order relations between the documents. The IHOSK is similar to the HOSK since they both propose a semantic kernel for SVM by using higher-order relations. However, IHOSK makes use of the higher-order paths between both the documents and the terms iteratively. Therefore, although, the performance of IHOSK is superior, its complexity is significantly higher than other higher-order kernels. A simplified model, the HOTK, uses higher-order paths between terms. In this sense, it is similar to the previously proposed term-based higher-order learning algorithms Higher-Order Naïve Bayes (HONB) (Ganiz et al., 2009) and Higher-Order Smoothing (HOS) (Poyraz et al., 2012, 2014).
In this article, we propose a novel approach for building a semantic kernel for SVM, which we name Class Meaning Kernel (CMK). The suggested approach smoothes the terms of a document in BOW representation (document vector represented by term frequencies) by class-based meaning values of terms. This in turn, increases the importance of significant or in other words meaningful terms for each class while reducing the importance of general terms which are not useful for discriminating the classes.
This approach reduces the above mentioned disadvantages of BOW and improves the prediction abilities in comparison with standard linear kernels by increasing the importance of class specific concepts which can be synonymous or closely related in the context of a class. The main novelty of our approach is the use of this class specific information in the smoothing process of the semantic kernel. The meaning values of terms are calculated according to the Helmholtz principle from Gestalt theory (Balinsky et al., 2010, 2011a, 2011b, 2011c) in the context of classes. We conducted several experiments on various document datasets with several different evaluation parameters especially in terms of the training set amount. Our experimental results show that CMK widely outperforms the performance of the other kernels such as linear kernel, polynomial kernel and RBF kernel. Please note that SVM with linear kernel is accepted as one the best performing algorithms for text classification and it virtually become de-facto standard in this domain. In linear kernel, the inner product between two document vectors is used as kernel function, which includes information about only the terms that these documents share. This approach can be considered as first-order method since its context or scope consists of a single document only. However, CMK can make use of meaning values of terms through classes. In this case semantic relation between two terms is composed of corresponding class-based meaning values of these terms for all classes. So if these two terms are important terms in the same class then the resulting semantic relatedness value will be higher. In contrast to the other semantic kernels that make use of WordNet or Wikipedia1 in an unsupervised fashion, CMK directly incorporates class information to the semantic kernel. Therefore, it can be considered a supervised semantic kernel.
One of the important advantages of the proposed approach is its relatively low complexity. The CMK is a less complex and more flexible approach than the background knowledge-based approaches, since CMK does not require the processing of a large external knowledge base such as Wikipedia or WordNet. Furthermore, since CMK is constructed from corpus based statistics it is always up to date. Similarly, it does not have any coverage problem as the semantic relations between terms are specific to the domain of the corpus. This leads to another advantage of CMK: it can easily be combined with background knowledge-based systems that are using Wikipedia or WordNet. As a result, CMK outperforms other similar approaches in most of the cases both in terms of accuracy and execution time as can be seen from our experimental results. The remainder of the paper is organized as follows: The background information with the related work including SVM, semantic kernels, and meaningfulness calculation summarized in Section 2. Section 3 presents and analyzes the proposed kernel for text classification algorithm. Experimental setup is described in Section 4, the corresponding experiment results including some discussion points are given in Section 5. Finally, we conclude the paper in Section 6 and provide a discussion on some probable future extension points of the current work.

- مقاله درمورد کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان
- پروژه دانشجویی کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان
- هسته معنایی برای طبقه بندی متون با ارزش واقعی اصطلاحات
- پایان نامه در مورد کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان
- تحقیق درباره کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان
- مقاله دانشجویی کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان
- کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان در قالب پاياننامه
- پروپوزال در مورد کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان
- گزارش سمینار در مورد کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان
- گزارش کارورزی درباره کرنل معنایی مجموعه ای از نوشته ها و داده ها برای دسته بندی متون از طریق بکارگیری ارزش واقعی واژگان