مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)

شابک پرینت: 9781467346870 وبسایت مرجع 16 رفرنس دارد
14,000 تومانشناسه فایل: 7499
چکیده
تحمل خطا، قابلیت اطمینان و دسترس پذیری در رایانش ابری برای حصول اطمینان از عملکرد درست و پیوسته از سیستم در حین خرابی ضروری است. در این مقاله، رویکردی برای ارزیابی مکانیزم های تحمل خطا ارائه می کنیم که از تکنولوژی مجازی سازی برای افزایش شفاف قابلیت اطمینان و دسترس پذیری برنامه های کاربردی مستقر در ماشین های مجازی در ابر استفاده می کند. در مقایسه با راه حل های موجود مختلف که خرابی های مستقل فرض می کنند، رفتار خرابی اجزای مختلف سرور، شبکه و توزیع توان در نمونه زیرساخت رایانش ابری، همبستگی بین خرابی های فردی و تاثیر هر خرابی بر برنامه های کاربردی کاربر را محاسبه می کنیم. ما از این ارزیابی برای مطالعه مکانیزم های تحمل خطا در زمینه های مختلف استقرار و به عنوان مبنای توسعه روش شناسی برای شناسایی و انتخاب مکانیزم های منطبق با نیازهای تحمل خطای کاربر استفاده می کنیم.
مقدمه مقاله
رایانش ابری در حال افزایش محبوبیت نسبت به سیستم های پردازش اطلاعات سنتی است. آن مزایای زیادی از لحاظ انعطاف پذیری در دستیابی و انتشار منابع محاسباتی، به شیوه ای موثر در هزینه عرضه می کند. به عنوان یک نتیجه، این پارادایم به ویژه برای استقرار برنامه های کاربردی با مقیاس پذیری، پردازش و ذخیره سازی بالا، گسترش یابد.
با توجه به محدودیت های اقتصادی، زیرساخت های ابری اغلب با استفاده از اجزای کالا ساخته می شوند و در نتیجه سخت افزار برای مقیاس و شرایط طراحی شده عرضه می شود. به علاوه، به خاطر پیچیدگی بسیار بالای سیستم، حتی مراکز داده دقیق مهندسی شده، تابع تعداد بزرگی از خرابی ها هستند، به ویژه زمانی که در مکان های مختلف توزیع می شوند. بعد ریسک های مربوط به برنامه های کاربردی کاربر، به طور قابل توجهی تغییر کرده است، زیرا خرابی ها در مراکز داده خارج از حدود سازماندهی کاربر می باشد. بنابراین روش های تحمل پذیری خطای سنتی کمتر موثر هستند و به همین خاطر نیاز فوری برای رفع نگرانی های قابلیت اطمینان و دسترس پذیری به عنوان یکی از مبانی بهبود امنیت کل سیستم خطا وجود دارد.
روش سنتی برای افزایش قابلیت اطمینان و در دسترس بودن نرم افزار، بکارگیری تکنیک های اجتناب ناپذیر از خطا و تحمل پذیری خطا در زمان توسعه است. در این رویکرد، کاربران بایستی معماری سیستم را در نظر بگیرند و بر اساس آن برنامه های کاربردی شان را بسازند. با این حال، جزئیات معماری سیستم، به خاطر لایه های مجرد و مدل تجاری رایانش ابری، به طور گسترده ای در دسترس نیست. به عنوان یک جایگزین، از رویکرد جدیدی از عرضه تحمل پذیری خطا به عنوان یک سرویس اضافی توسط شخص ثالث یا فراهم کننده سرویس، حمایت شده است. این روش جدید، مکانیزم های تحمل پذیری خطای موجود را اهرم می نماید که از تکنولوژی مجازی سازی و قابلیت هایش برای تکرار شفاف و مهاجرت نمونه ماشین های مجازی (VM) استفاده می کند.
در این راستا، ما یک چارچوب مفهومی مدیر تحمل خطا (FTM) را توسعه دادیم که شامل تمام اجزای لازم و ضروری برای تحقق رویکرد جدید می شود.
در این مقاله، ما بر اساس اصول FTM و راه حلی در مورد دو جنبه مهم از سرویس ارائه می کنیم که پیش از آن تحلیل نشده بودند. ابتدا، روشی برای اندازه گیری اثربخشی مکانیزم تحمل خطای ساخته شده با استفاده از تکنولوژی مجازی سازی ارائه می کنیم. برای دستیابی به هدف، سطح قابلیت اطمینان و دسترس پذیری بدست آمده با استفاده از مکانیزم تحمل خطای خاص در سطوح مختلف استقرار با استفاده از درختان خطا و مدل های مارکوف را ارزیابی می کنیم. سپس، با در نظر گرفتن معیار اثربخشی، روشی برای انتخاب مکانیزم های تحمل خطا ارائه می دهیم که با نیازهای کاربر مطابقت دارد ( که در مرحله اول بدست آمده ). این فرایند تطبیق برای پشتیبانی درست از تحمل خطا از سوی FTM ضروری است.
باقیمانده مقاله حاضر به این شرح است. بخش دوم، سناریوی انگیزشی را شرح می دهد. بخش سوم یک نمای کلی از نمونه زیرساخت ابری مطرح کرده، رفتار خرابی اجزای بحرانی سیستم و تاثیر آنها بر سرویس را نشان می دهد. در بخش 4 در مورد مکانیزم های تحمل خطا مورد بحث قرار می گیرد که از تکنیک های مجازی سازی برای دستیابی به تحمل پذیری خطا استفاده کرده و سناریوهای استقرار ممکن را توصیف می کند. بخش 5 شیوه ای برای شناسایی و انتخاب تکنیک های تحمل خطا بر اساس نیازهای کاربر مطرح می کند. بخش 6 کارهای مرتبط را جمع بندی کرده و بخش 7 نتیجه گیری را در بر می گیرد.
ABSTRACT Fault tolerance management in IaaS (Infrastructure as a service) clouds
Fault tolerance, reliability and availability in Cloud computing are critical to ensure correct and continuous system operation also in the presence of failures. In this paper, we present an approach to evaluate fault tolerance mechanisms that use the virtualization technology to transparently increase the reliability and availability of applications deployed in the virtual machines in a Cloud. In contrast to several existing solutions that assume independent failures, we take into account the failure behavior of various server components, network and power distribution in a typical Cloud computing infrastructure, the correlation between individual failures, and the impact of each failure on user’s applications. We use this evaluation to study fault tolerance mechanisms under different deployment contexts, and use it as the basis to develop a methodology for identifying and selecting mechanisms that match user’s fault tolerance requirements.
Introduction
Cloud computing is gaining an increasing popularity over traditional information processing systems. It offers immense benefits in terms of flexibility in obtaining and releasing computing resources, as and when required, in a cost-effective manner. As a consequence, this paradigm is widely being used particularly to deploy applications with high scalability, processing and storage requirements.
Due to economic limitations, Cloud infrastructures are often built using commodity components, and as a consequence, the hardware is exposed to scale and conditions it was not originally designed for [13]. Furthermore, due to very high system complexity, even carefully engineered data centers are subject to a large number of failures, especially when they are distributed in several locations. The dimension of risks on user’s applications is significantly changed since failures in the data centers are outside the scope of user’s organization. Traditional fault tolerance approaches are therefore less effective, and there is a pressing need to address user’s reliability and availability concerns as one of the basis to improve the overall system’s security.
The traditional way to increase reliability and availability of software is to employ robust fault avoidance and fault tolerance techniques at development time. In this approach, users must take into account the system architecture and build their applications accordingly. However, the system’s architectural details are not widely available to the users because of the abstraction layers and business model of Cloud computing.
As an alternative, a new perspective of offering fault tolerance as an additional service either by a third party or the service provider itself is being advocated [6], [7], [9]. This new approach leverages existing fault tolerance mechanisms that use virtualization technology and its capabilities to transparently replicate and migrate virtual machine (VM) instances. In this direction, we developed a conceptual framework, the Fault Tolerance Manager (FTM), which includes all the components necessary to realize the new perspective [6].
In this paper, we build on the principles of the FTM, and present a solution on two important aspects of the service that were not analyzed previously. First, we present an approach to measure the effectiveness of a fault tolerance mechanism built using the virtualization technology. To achieve this, we evaluate the level of reliability and availability that can be obtained by using a particular fault tolerance mechanism at different deployment levels using fault trees [12] and Markov models. Second, we present a methodology to select the fault tolerance mechanisms that most appropriately match user’s requirements by considering the effectiveness measure (that is obtained in the first step). This matching process is essential for the FTM to correctly deliver the fault tolerance support.
The remainder of the paper is as follows. Section II describes the motivating scenario. Section III presents an overview of a typical Cloud infrastructure, outlines the failure behavior of critical system components and their impact on the service. Section IV discusses representative fault tolerance mechanisms that use virtualization techniques to transparently obtain fault tolerance and describes possible deployment scenarios. Section V presents an approach to identify and select fault tolerance techniques based on user’s requirements. Section VI summarizes the related work and Section VII outlines our conclusions.
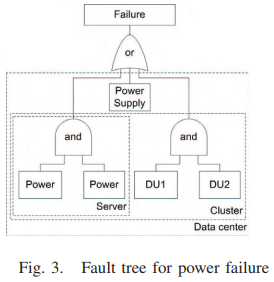
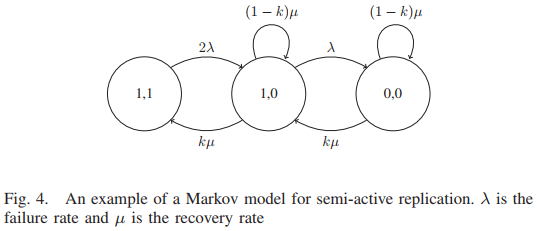
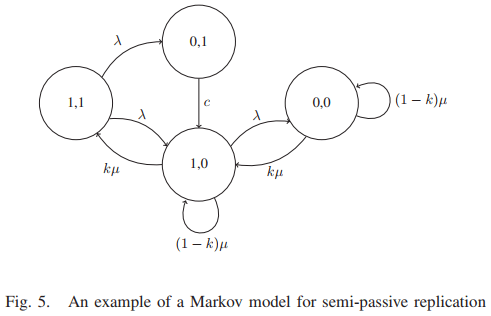
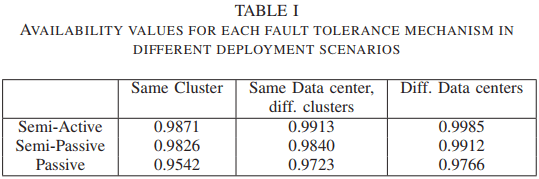
- مقاله درمورد مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)
- مدیریت تحمل شکست در ابرهای IaaS
- پروژه دانشجویی مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)
- مروری بر مدیریت تحمل پذیری خطا در ابرهای IaaS
- پایان نامه در مورد مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)
- تحقیق درباره مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)
- مقاله دانشجویی مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)
- مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS) در قالب پاياننامه
- پروپوزال در مورد مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)
- گزارش سمینار در مورد مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)
- گزارش کارورزی درباره مدیریت تحمل خطا در سرویس های زیرساخت ابری (IaaS)